mongodbのIndex(転載メモ)
MongoDBのインデックス
このドキュメントはMongoDB 2.6を前提にしています
インデックスとは
例えば1億件のドキュメントからnameがwatanabeであるドキュメントを検索することを考えます
- インデックスが無ければ
- 全てのドキュメントの中を一つづつ見なければnameがwatanabeのドキュメントを見つけることができません。
- 辞書で単語を1ページ目から順番に探すイメージです
処理時間はドキュメント数に比例します。いわるゆ O(N) です
インデックスがあると
- nameがwatanabeであるドキュメントの物理的な位置を既に知っているため、すぐにドキュメントを見つけられます
- 辞書の索引を引くイメージです
- 処理時間はドキュメント数に比例しません。いわゆる O(1) です
インデックスはDBのパフォーマンスチューニングで、最も基本で最も重要!!!
MongoDBとて例外ではない!!
インデックスの実態
- MongoDBのインデックスはB-Tree(平衡木)です。(いまのところ)
- MongoDBのインデックスはデータファイルの中に保存されます。
インデックスの注意点
- インデックスは読込は速くなりますが、書込みは遅くなります。
- 非効率なインデックスは性能を下げます。(例えば性別をインデックスにする等)
- インデックスがメモリに乗っていれば高速ですが、インデックスがメモリに乗らない状況だとディスクIOが発生するためより低速になります。インデックスとよく使うデータ(いわゆる「ワーキングセット」)がメモリに乗っている状態が理想です。
インデックスの種類
- 単一:一つのキーに対してインデックスを付与。主キー以外でインデックスを作成可能。
- 複合:複数のキーに対してインデックスを付与。順序があるため、
{a:1,b:1}と{b:1,a:1}ではインデックスの構造が異なる。 - マルチキー:配列の要素に対してインデックスを作成する
- 地理空間:地理情報(緯度経度)、空間情報(点、直線、多角形)に対して専用のインデックスを張り、地理空間用のクエリに対応させる。
- テキスト:アルファベットに対して全文検索のインデックスを作る。日本語データには対応していない。
- ハッシュ:キーに対してハッシュ関数を適用して、その値をインデックスに用いる。シャーディング環境において、偏りのあるキーを均等に分散させたい場合に利用するとよい。
※)地理空間インデックスは、手前みそですが私のQiitaの投稿がわかりやすいと思います。
インデックスの属性
- ユニーク属性:同じ値がすでにある場合は、挿入できない(※)
- スパース属性:trueにすると、インデックスに指定したキーを持っているドキュメントにのみ付与される。全てのドキュメントがそのキーを持っているとは限らない場合に、trueを指定すると、インデックスサイズの削減ができる。
※)シャーディング環境ではシャードキーを先頭に含む複合キーしかユニーク属性を指定できません。
試してみよう
MongoDBに接続
$ mongo
100万件のデータの準備
ary = []
for(var i = 0 ; i < 1000000; i++){ ary.push({number: i}) }
ary.length
=> 1000000であることを確認
データの挿入
db.col.insert(ary)
データの確認
db.col.find() db.col.count()
numberが2000のドキュメントを検索
db.col.find({number:2000})
一見速いように見えるが、実は超遅い
explain()メソッドで、クエリの実行計画をみる
db.col.find({number:2000}).explain()
=>以下の出力
{
"cursor" : "BasicCursor", ←Indexを使っていない
"isMultiKey" : false,
"n" : 1,
"nscannedObjects" : 1000000, ←百万件のスキャン
"nscanned" : 1000000,
"nscannedObjectsAllPlans" : 1000000,
"nscannedAllPlans" : 1000000,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 7812,
"nChunkSkips" : 0,
"millis" : 305, ←305ミリ秒(遅い)
"server" : "xxx:27017",
"filterSet" : false
}
インデックスを張ってみる
db.col.ensureIndex( { number : 1 } )
=> "ok" : 1 を確認
インデックスを参照
db.col.getIndexes()
再度検索
db.col.find({number:2000})
db.col.find({number:2000}).explain()
=> 以下の出力
{
"cursor" : "BtreeCursor number_1", ←name_1というB-Treeインデックスを使っている
"isMultiKey" : false,
"n" : 1,
"nscannedObjects" : 1, ←スキャンオブジェクトが一つ
"nscanned" : 1,
"nscannedObjectsAllPlans" : 1,
"nscannedAllPlans" : 1,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 0, ←0msになった!
"indexBounds" : {
"number" : [
[
2000,
2000
]
]
},
"server" : "xxx:27017",
"filterSet" : false
}
速くなりました!
ソートを含むクエリとインデックス
sort()や$orderbyオプションを含むクエリはソートするクエリです。 この場合、ソートキーが先頭に来るような複合インデックスでなければクエリでは使われません。
試してみよう
データの挿入
db.hoge.insert({a:1, b:1, c:1})
db.hoge.insert({a:2, b:3, c:1})
db.hoge.insert({a:1, b:3, c:2})
db.hoge.insert({a:2, b:1, c:3})
db.hoge.insert({a:1, b:2, c:2})
db.hoge.insert({a:2, b:2, c:1})
db.hoge.find()
インデックスの有効化
db.hoge.ensureIndex({a:1,b:1,c:1})
このデータに対してbで絞り込んで、cで並び変える
db.hoge.find({b:2}).sort({c:1}).explain()
{
"cursor" : "BasicCursor", ←インデックスを使っていない
...
"scanAndOrder" : true, ←外部ソートしている
このデータに対してbで絞り込んで、aで並び変える
db.hoge.find({b: {$gt:2}}).sort({a:1}).explain()
{
"cursor" : "BtreeCursor a_1_b_1_c_1", #インデックスを使っている
...
"scanAndOrder" : false, ←外部ソートしていない
なぜ結果が違うのか?絵で見てみよう。
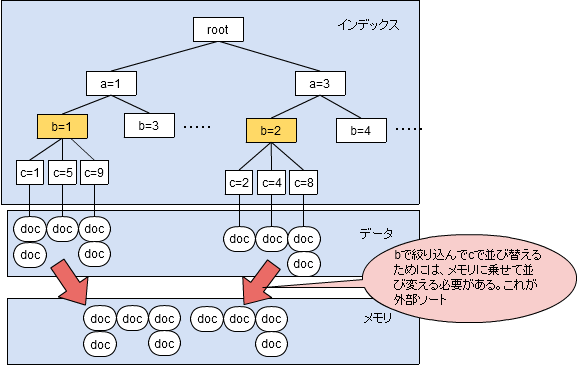
この外部ソートに32MByteのメモリ制限がある。16MBのドキュメントだとインデックスなしでは2つしかソートできない。
最後に
今回は軽く触りを触れましたが、インデックスはまだまだ複雑です。 特に以下のような状態ではインデックスはさらに複雑になります。
- 集計(aggregation)とインデックス
- シャーディングとインデックス
常にexplain()で実行計画を見て適切なインデックスが使われているか見る癖をつけましょう。
あと、MongoDB 2.6の新機能で、一つのクエリで複数のインデックスを使う「Index Intersection」が出ました。これはまだ未知数です。。。